はじめに|G検定とディープラーニング要素技術の重要性

G検定は、日本ディープラーニング協会(JDLA)が主催するAIリテラシー試験です。
2025年版シラバスではディープラーニングの要素技術が大幅に拡充され、合否を左右する最重要パートとなっています。
ここでは、なぜ要素技術の深い理解が点数に直結するのか、その背景とメリットを整理します。
ディープラーニング要素技術が試験配点で占める割合
- 新シラバスでは全問題の約30%が畳み込み層・プーリング層・アテンションなどの要素技術から出題されます。
- 要素技術は理論と実装の両面を問われるため、表面的な暗記だけでは太刀打ちできません。
G検定合格後に活きる二つの武器
- 実務適用力
プロジェクトでモデルの構造を説明し、ボトルネックを特定できる人材は希少です。
要素技術を体系的に理解することで、実装からチューニングまで自走できるスキルが身に付きます。 - キャリアの拡張性
E資格や生成AI関連資格にステップアップする際、要素技術の知識が橋渡しとなります。
変化の激しいAI業界で、学び直しコストを最小化できます。
本記事で得られるもの
- 全結合層からアテンションまで、2025年シラバスのキーワードを網羅的に整理できます。
- 試験本番で即答できる記憶定着法と学習ロードマップを手に入れられます。
- 学習後すぐに実務応用できる実装ヒントや最適化のコツを習得できます。
次章からは、まず全結合層と畳み込み層の構造を比較しながら、パラメータ計算や活用シーンを具体的に解説していきます。
全結合層から畳み込み層へ 構造とパラメータ計算を理解する
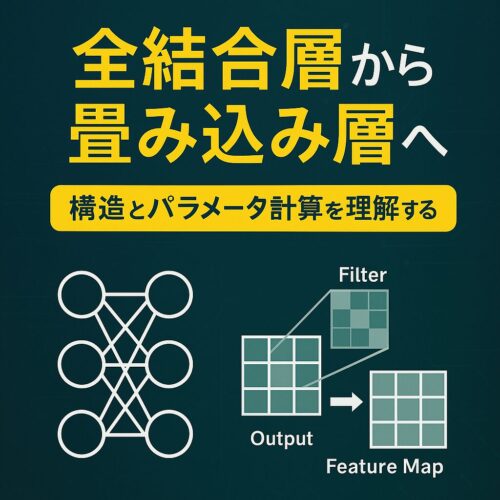
全結合層(Dense Layer)の仕組みとパラメータ数
全結合層は「入力のすべての要素が出力ニューロンすべてに接続」される層です。
パラメータ数は
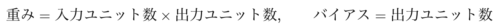
で求められ、合計は (入力+1)×出力となります。
例として、28×28ピクセルの手書き画像(784 次元)を 256 ユニットへ変換する場合、
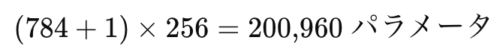
を学習する必要があります。
画像が大型化するとパラメータは爆発的に増え、メモリ消費と計算負荷が急上昇するのが難点です。
畳み込み層(Convolution Layer)の仕組みとパラメータ数
畳み込み層は画像の局所領域に小さなフィルタ(カーネル)をスライド適用して特徴マップを生成します。
パラメータ数は
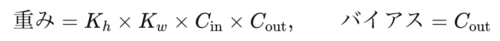
となり、カーネルサイズとチャンネル数にしか依存しないのがポイントです。
例えば 3×3カーネル、入力チャンネル 3、出力チャンネル 64 の場合、
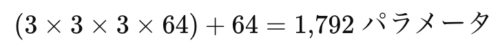
で済みます。
全結合層と比較すると桁違いに少なく、計算量も低減できます。
全結合層と畳み込み層の比較早見表
| 項目 | 全結合層 | 畳み込み層 |
|---|---|---|
| 接続方式 | 全ユニット同士 | 局所領域+重み共有 |
| パラメータ依存 | 入力サイズに比例 | カーネルサイズに比例 |
| 代表用途 | 出力層・タブular データ | 画像・音声・時系列前段 |
| 長所 | 高い表現力・非線形結合 | 計算効率・位置不変性 |
| 短所 | パラメータ爆発・過学習 | 大域的関係を直接捉えにくい |
重み共有と局所受容野が生む三つのメリット
- パラメータ削減
重み共有により、同じ特徴検出器を画像全域に適用できます。 - 位置不変性
畳み込みとプーリングの組み合わせで、物体の位置ズレに頑健なモデルを構築できます。 - 学習データ効率
学習すべきパラメータが少ないため、少量データでも過学習しにくく、高速収束が期待できます。
ストライド・パディング・ダイレーションを理解する
- ストライドを大きくすると出力サイズが縮小し計算量が減りますが、詳細な情報が失われやすくなります。
- パディングは画像端の情報保持や出力サイズ調整に用いられ、
sameとvalidの二通りが代表的です。 - ダイレーション(空洞)畳み込みはフィルタ間隔を空けて視野を拡大し、パラメータ数を増やさず長距離依存を捉えられます。
深層化時代のトレンド:軽量畳み込み
- Depthwise Separable Convolution(MobileNet 系)
- 通常畳み込みを深さ方向×1×1 で分解し、パラメータ・FLOPs を 1/8〜1/9 に削減します。
- Group Convolution(ResNeXt 系)
- チャンネルをグループに分割して並列畳み込み、精度維持と高速化を両立します。
これらはモバイル端末やエッジデバイス向けのモデル設計で頻出します。
G検定でも「パラメータ削減手法を選べ」という設問が定番化しているため、キーワードを紐づけて覚えておくと得点源になります。
まとめ
- 全結合層は高い表現力を持つ一方でパラメータ爆発が課題です。
- 畳み込み層は重み共有と局所受容野により効率的かつ位置不変な特徴抽出を実現します。
- ストライド・パディング・ダイレーションの設定がモデル容量と精度を左右します。
- 軽量畳み込みはエッジ AI の鍵となり、2025 年以降の G検定でも注目度が高い分野です。
次章では、学習を加速し汎化性能を引き上げる活性化・正規化・プーリング層の役割とベストプラクティスを詳しく解説します。
活性化・正規化・プーリング層で学習を加速し汎化性能を高める

活性化関数でネットワークに非線形性を注入します
活性化関数は層ごとの線形変換に非線形性を与え、ネットワークが複雑なパターンを学習できるようにします。
中間層には ReLU を基本とし、勾配が流れにくい場合は Leaky ReLU や ELU に切り替えると学習が安定します。
出力層では、二値分類なら シグモイド、多クラス分類なら Softmax を使うのが王道です。
| 代表関数 | 長所 | 留意点 | 主な用途 |
|---|---|---|---|
| ReLU | 計算が軽い・勾配爆発を抑制 | 0 以下で勾配 0 に注意 | CNN 中間層全般 |
| Leaky ReLU | 死んだニューロンを緩和 | 傾き α の調整が必要 | ReLU が停滞したとき |
| ELU | 出力平均 0 付近→収束高速 | 実装が複雑 | 深層残差ブロック |
| Softmax | 出力を確率分布化 | 多クラス限定 | 出力層 |
正規化層で勾配を安定させます
正規化は入力分布の揺らぎを抑え、勾配消失を防ぐ役割を果たします。
| 手法 | 仕組み | 適したシナリオ |
|---|---|---|
| バッチ正規化 | ミニバッチ単位で平均・分散を標準化 | CNN と MLP 全般 |
| レイヤー正規化 | サンプル単位でチャネル方向に標準化 | RNN・Transformer |
| グループ正規化 | チャネルをグループ化して標準化 | 小バッチ CNN |
| インスタンス正規化 | 画像ごとにチャネル正規化 | スタイル変換 |
バッチサイズが小さい場合はバッチ正規化が不安定になるため、グループ正規化やレイヤー正規化に切り替えると効果的です。
プーリングで特徴を集約し次元を削減します
プーリング層は畳み込みで得られた特徴マップを要約し、モデルを位置ずれに強くします。
| 種類 | 特徴 | 利点 |
|---|---|---|
| 最大プーリング | 局所領域の最大値を抽出 | エッジなど強い特徴を強調 |
| 平均プーリング | 局所平均を計算 | ノイズに強く滑らかな要約 |
| グローバルアベレージプーリング | マップ全体を 1 値に縮約 | 全結合層不要でパラメータ削減 |
グローバルアベレージプーリングは分類タスクで全結合層を置き換え、パラメータ数を大幅に削減できるため近年主流になっています。
実装ベストプラクティス五箇条
- Conv → BatchNorm → ReLU の順序を基本形とします。
- ドロップアウトは 畳み込み層より後の全結合層で使用すると効果が高いです。
- 最大プーリングとストライド 2 の畳み込みは計算量を見ながら使い分けます。
- レイヤー正規化を導入した Transformer では 残差接続前の正規化が安定します。
- モバイル向けモデルは DepthwiseConv → BatchNorm → ReLU6 が省電力の定番です。
まとめ
- 活性化関数は非線形性を担い、ReLU 系がデフォルトです。
- 正規化層で勾配の流れを整え、バッチサイズに応じて手法を選択します。
- プーリング層で特徴を集約し、計算コストと汎化性能を両立します。
ここまでで、ディープラーニングの「中核三役」である活性化・正規化・プーリングの役割を体系的に理解できました。
次章では、ネットワーク深層化を可能にした スキップ結合とレジジュアルネットワーク の仕組みと活用事例を解説します。
スキップ結合とレジジュアルネットワーク 深層化を支える残差学習

スキップ結合とは
スキップ結合は、ある層の出力を後段の層へ直接足し合わせたり連結したりする接続方法です。
これにより誤差逆伝播の経路が短縮され、勾配消失を大幅に緩和できます。
数式では、
入力 x をそのまま出力 F(x)に足し合わせた
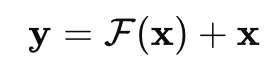
という形が代表的です。
実装上は torch.nn.Identity() を経由して加算するだけなので手間はかかりません。
残差学習のメリット
- 深層化のブレークスルー
100 層を超えるネットワークでも収束可能となり、画像分類では ResNet-152 が ILSVRC 2015 で優勝しました。 - 学習速度の向上
恒等マッピングを学習する場合、残差 F(x)が 0 に近づくだけで済むため最適化が高速化します。 - 転移学習の汎用性
低層が一般的特徴を、高層がタスク固有特徴を学習しやすくなるため、他タスクへのファインチューニングが容易です。
レジジュアルブロックの構造
標準的な ResNet Basic Block はConv3×3 → BatchNorm → ReLU → Conv3×3 → BatchNorm にスキップ結合を加算し、最後に ReLU を適用します。
深いモデルでは Bottleneck Block を採用し、1×1 → 3×3 → 1×1 の三段構成で計算量とパラメータを圧縮します。
Input
│
├─ Conv1×1, BN, ReLU
├─ Conv3×3, BN, ReLU
├─ Conv1×1, BN ─┐
│ │ ← Identity (場合により1×1 Convで整形)
└─────── Add ──┴─ ReLU ─→ Output
バリエーションと応用例
| モデル | 特徴 | 主な用途 |
|---|---|---|
| ResNet-50/101/152 | Bottleneck + Identity Shortcut | 画像分類・検出 |
| Wide ResNet | チャンネル幅を拡大し深さを縮小 | 学習を高速化 |
| DenseNet | 全層連結で情報と勾配を最大共有 | 医療画像・小規模データ |
| UNet | U 字型で高解像度特徴を復元 | セグメンテーション |
| Highway Network | ゲート付きスキップで情報調整 | 自然言語処理(初期) |
実装時のチェックポイント
- チャネル数が変わる場合は
1×1畳み込みでスキップ経路を整形します。 - BatchNorm の順序は「Conv → BN → ReLU」を基本とし、スキップ後にもう一度 ReLU を入れるのが一般的です。
- Gradient Check を行い、加算前後で勾配が消えていないかを確認します。
まとめ
- スキップ結合は深いネットワークでも勾配を保ち、学習を安定化します。
- 残差学習により「深さ=表現力」を真に活かせるようになりました。
- ResNet 系のバリエーションを知っておくと、試験の「最適な構造を選べ」設問に即答できます。
次章では、長期依存を捉える RNN とアテンション機構、そしてトランスフォーマーがどのようにディープラーニングの地平を広げたかを解説します。
RNNとアテンション トランスフォーマーで長期依存と文脈を制す

RNNの基本構造と課題を把握します
リカレントニューラルネットワーク(RNN)は、過去の出力を隠れ状態として保持しながら入力を逐次処理するため、時系列・テキスト・音声など順序依存データの解析に強みがあります。
ただし長い系列では 勾配消失/爆発 が発生しやすく、BPTT(Backpropagation Through Time)の計算コストも増大します。
| モデル | 特徴 | 長所 | 短所 |
|---|---|---|---|
| Elman RNN | 隠れ状態を再帰接続 | 実装が簡単 | 長期依存に弱い |
| LSTM | 入力・忘却・出力ゲート | 長期依存を記憶 | パラメータ多い |
| GRU | ゲート2つで簡素化 | 計算軽量 | 性能はLSTM並み |
実装のコツ
- Pytorch の
nn.LSTMでbidirectional=Trueを指定すると双方向化できます。- 勾配爆発対策として
clip_grad_norm_を毎ステップ呼ぶと安定します。
アテンション機構がもたらしたブレークスルー
アテンションは「入力系列の重要度を動的に学習する重み付け機構」です。
翻訳であれば、ある単語を出力する際に元文のどの単語に注目するかを学習します。
- クエリ(Q)・キー(K)・バリュー(V) の内積で類似度を算出し、Softmax で確率化して重み付け平均します。
- RNN では隠れ状態に情報が圧縮されがちですが、アテンションは全入力を直接参照するため長距離依存をスムーズに扱えます。
トランスフォーマーのセルフアテンションとマルチヘッド
トランスフォーマーは 畳み込みも再帰も使わずアテンションだけで系列を処理します。
- セルフアテンション:系列内の単語同士の関連度を同時に計算し、高速並列化が可能です。
- マルチヘッド:異なる表現空間でアテンションを複数回実行し、多様な文脈情報を取り込めます。
- 位置エンコーディング:サイン波や学習可能ベクトルを用いて単語の順序を埋め込みます。
| 層 | 処理内容 |
|---|---|
| Encoder | Self-Attention → Add & Norm → FFN → Add & Norm(×N) |
| Decoder | Masked Self-Attention → Add & Norm → Encoder–Decoder Attention → Add & Norm → FFN → Add & Norm (×N) |
利点
- GPU 並列効率が高く、事前学習+微調整に最適
- 大規模データで性能が指数関数的に伸びるスケーリング性
オートエンコーダと自己教師あり学習 特徴量抽出と生成モデルの最前線
オートエンコーダの基本構造
オートエンコーダ(AE)は Encoder で圧縮 → Decoder で復元 の自己符号化ネットワークです。
復元誤差を最小化することで、ラベルなしでも特徴表現を獲得できます。
| バリエーション | 目的 | 特徴 |
|---|---|---|
| Stacked AE | 深層化で高次特徴 | 逐次事前学習+微調整 |
| Variational AE | 生成モデル | 潜在分布を正規分布へ整形 |
| β-VAE | 解釈可能潜在 | KL 項に係数 β で独立性強化 |
| InfoVAE | 情報最大化 | 再構成と情報量を両立 |
| VQ-VAE | 離散潜在 | コードブックで離散表現化 |
試験頻出ポイント
- VAE は「確率的潜在変数を持つ自己符号化器」と一言で説明できるようにします。
- β-VAE の β を大きくすると潜在変数が分離しやすくなることを覚えます。
自己教師あり学習との相性
大型言語モデルやビジョンモデルでは、AE を基盤とした自己教師あり事前学習が主流です。
事前学習で獲得した汎用特徴は少量データの下流タスクへ転移しやすく、学習コストとデータ依存を大幅に削減します。
データ拡張とハードウェア最適化で汎化性能を最大化する
代表的データ拡張テクニック早見表
| 分野 | 画像 | 音声 | テキスト |
|---|---|---|---|
| 幾何変換 | ランダムローテートランダムクロップ | Time Stretch | ワードシャッフル |
| 色・輝度 | コントラスト調整ブライトネス変化 | ピッチシフト | 同義語置換 |
| 破壊型 | カットアウトランダムイレイシング | 周波数マスキング | マスク言語モデル |
| 合成型 | MixUpCutMix | SpecAugment | Back-Translation |
| 自動探索 | RandAugmentAutoAugment | ー | ー |
ポイント
- 画像分類では MixUp/CutMix が最小限の実装で大きな精度向上をもたらします。
- テキストは パラフレージング と マスク言語モデル がデータ多様性を高めます。
ハードウェア最適化のチェックリスト
- Mixed Precision(FP16/BF16) を有効化してメモリと演算を半減させます。
- Gradient Accumulation で小 VRAM でも大バッチ効果を再現できます。
- TensorRT / XLA など推論最適化コンパイラを利用し、レイテンシを短縮します。
- 量子化 (INT8/INT4) でモバイル・エッジ向けにモデルを軽量化します。
まとめ 学習ロードマップと試験合格への最短ルート
- 基礎理解(1週目)
全結合層・畳み込み層・プーリングを図解で暗記します。 - 応用習得(2〜3週目)
スキップ結合とアテンションの数式を手書きで再現し、Colab で実装を動かします。 - 実装演習(4週目)
オートエンコーダとデータ拡張を組み合わせ、CIFAR-10 で 90% 以上を目標にします。 - 過去問+模試(5週目)
90 分 160 問を時間内に解き切る練習で本番感覚を養います。
当日スコアメイク三原則
- 即答可能問題を30分で回収して精神的優位を確保します。
- シナリオ問題は図に落として因果を整理し、選択肢を消去法で絞ります。
- 終了5分前にマーク漏れチェックでケアレスミスを防ぎます。
これでディープラーニング要素技術を中心とした G検定対策が完了です。
あとはロードマップに沿って行動し、合格証をキャリアの新たなスタートラインに変えてください。
応援しています。
>今回紹介したG検定の学習内容以外を学びたい方は、こちらからご覧ください👇
