G検定ディープラーニング分野が合否を左右する理由

G検定は、日本ディープラーニング協会(JDLA)が実施するAIリテラシー資格であり、2025年は年6回開催されます。
直近の試験(2025年5月実施)では受験者4,284名中3,501名が合格し、合格率は約82%と発表されました。
数字だけ見ると合格しやすい印象を受けますが、実際には各分野で「落とせない得点源」を確実に拾えるかどうかが明暗を分けます。
その中でもディープラーニング分野は全体の約3分の1を占め、配点比率が最も高いため、ここで取りこぼすと一気に不合格圏へ転落しかねません。
JDLAの最新シラバス(2024改訂→2025適用)では、ニューラルネットワークの基礎だけでなく活性化関数・誤差関数・正規化・最適化アルゴリズム・計算リソース(GPU/TPU)まで理解の深さが問われます。
従来の暗記中心の学習では対応しきれず、概念をストーリーで説明できるレベルに仕上げることが必須です。
さらに2025年は3・7・11月回が2日間開催となり、社会人が受験日を選びやすい一方で、直前期に受験者が集中しやすくなります。
余裕を持った計画でディープラーニング分野を仕上げておくことで、模試や過去問演習の数も確保でき、合格確率が大幅に上がります。
本シリーズでは、ディープラーニング分野を「基礎概念→学習メカニズム→性能向上テクニック→計算資源」の4ステップで体系的に解説し、試験本番で即答できるレベルまで引き上げます。
まずはニューラルネットワークとディープラーニングの基礎を整理し、スコアメイクの土台を固めましょう。
ニューラルネットワークとディープラーニングの基礎を押さえる

ニューラルネットワークの構造を分解して理解する
ニューラルネットワークは、入力層・隠れ層・出力層という三つの層で構成されます。
入力層ではデータを受け取り、隠れ層で特徴を抽出し、出力層で予測を出力します。
隠れ層が一つだけの単純パーセプトロンは線形分離可能な問題しか扱えませんが、隠れ層を二層以上重ねた多層パーセプトロン(MLP)は非線形問題にも対応できます。
ディープラーニングとは何か
隠れ層を深く積み重ね、大量のパラメータで複雑な特徴を学習するアプローチがディープラーニングです。
画像や音声、自然言語など高次元・非構造データの学習に強く、従来の機械学習では難しかったタスクで高精度を実現しています。
- 画像認識: 畳み込みニューラルネットワーク(CNN)が自動でエッジや形状を抽出し、分類精度を向上させます。
- 自然言語処理: 再帰型ネットワークやトランスフォーマーが文脈を捉え、翻訳や要約で人並みの性能を達成しています。
- 表形式データ: 勾配ブースティングが優位な領域でも、ディープラーニングのアンサンブルで精度をさらに上げる事例が増えています。
ディープラーニングが強力な三つの理由
- 階層表現学習
低レベル特徴(エッジ)→中レベル特徴(パターン)→高レベル概念(物体)のように、抽象度を階段状に高めながら学習します。 - 膨大なパラメータと計算資源
GPU・TPUによる並列演算で、1億を超える重みでも数時間で学習が可能です。 - エンドツーエンド学習
特徴量エンジニアリングを最小化し、「データ投入→予測出力」までを一貫して最適化できます。
ニューラルネットワークの数学的視点
ネットワーク全体は、行列演算と非線形変換の繰り返しとして表現できます。
入力ベクトル x に重み行列 W とバイアス b を掛け、活性化関数 f を適用する式は
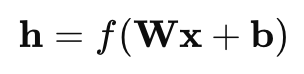
です。
層を重ねるたびに新たな W, b が追加され、最終層の出力が予測値となります。
ディープラーニングではこれを数十〜数百層規模で積み重ねるため、誤差逆伝播法による効率的な勾配計算と最適化アルゴリズムが不可欠です。
実務での適用条件
- データ量: 数万〜数百万サンプルが望ましく、データ拡張や転移学習で補完することもあります。
- 計算資源: 単一GPUなら8〜24GBのVRAMが目安です。クラウド環境でTPUを利用すると学習時間を大きく短縮できます。
- ビジネス要件: モデル精度だけでなく、推論速度や消費電力、解釈性のバランスを考慮します。
学習のポイントまとめ
- 層構造と計算の流れを図解で整理する
- 活性化関数・誤差関数をセットで暗記する
- 小規模ネットワークを実装してみる(MNIST手書き数字など)
- GPUで学習時間がどの程度短縮されるか体験する
ここまでで、ディープラーニングの基礎構造と強みを体系的に理解できました。
次章では、モデルの表現力を決定づける活性化関数の種類と使い分けを詳しく解説します。
活性化関数の種類と使い分けポイントを理解する

活性化関数は、ニューラルネットワークに非線形性を与えて表現力を飛躍的に高める重要パーツです。
どの関数を選ぶかで収束速度や精度、勾配消失・爆発のリスクが大きく変わります。
ここでは代表的な六つの活性化関数を俯瞰し、G検定で問われやすい「選択理由」と「注意点」を整理します。
| 関数 | 数式イメージ | 長所 | 短所 | 主な用途 |
|---|---|---|---|---|
| シグモイド | σ(x)=1/(1+e−x)\sigma(x)=1/(1+e^{-x}) | 出力が0〜1で確率解釈が容易 | 勾配消失が起きやすい | 出力層(二値分類) |
| tanh | tanh(x)=ex−e−xex+e−x\tanh(x)=\frac{e^{x}-e^{-x}}{e^{x}+e^{-x}} | 中心が0で学習が安定 | シグモイド同様に勾配消失 | RNNの中間層(小規模) |
| ReLU | max(0,x)\max(0,x) | 計算が軽い・勾配爆発を抑制 | 0以下で勾配0→死んだニューロン問題 | CNN・MLPの中間層 |
| Leaky ReLU | max(αx,x)\max(\alpha x,x) | 負領域に傾き→死活問題を緩和 | α\alpha設定が経験則 | ReLUの改良版として汎用 |
| ELU | x>0:x, x≤0:α(ex−1)x>0:x,\ x\le0:\alpha(e^{x}-1) | 出力平均0付近→収束が速い | 実装やや複雑 | 深層CNN・残差接続と相性良 |
| Softmax | softmax(zi)=ezi∑jezj\text{softmax}(z_i)=\frac{e^{z_i}}{\sum_j e^{z_j}} | 多クラス確率を一括出力 | 出力層専用で勾配が絡みやすい | 多クラス分類の出力層 |
選定フローを覚えると迷わない
- 中間層ならまず ReLU を採用し、学習停滞が見えたら Leaky ReLU や ELU に切り替えます。
- 出力が確率の場合、二値分類はシグモイド、多クラス分類は Softmax が定番です。
- RNN 系でシーケンス長が短いときは tanh、それ以上に長い系列や勾配流れの問題が顕著なときはゲート付きユニット(GRU・LSTM)に移行します。
試験で狙われるポイント
- ReLU が主流の理由を 1 行で説明できるか
→「計算が速く勾配が 0 になりにくいので深層でも学習が進む」 - Softmax とシグモイドの違いを即答できるか
→「Softmax は出力が互いに排他的な多クラス分類に、シグモイドはラベルが独立した二値分類に」 - 死んだニューロン問題の対策を列挙できるか
→Leaky ReLU、Parametric ReLU、適切な初期値設定、学習率スケジューラなど
実装で理解を深める
- Colab で MNIST を ReLU と Leaky ReLU で比較し、エポックごとの損失推移を可視化する。
- Softmax 出力で予測確率トップ5を表示し、「信頼度が低い原因」を勾配チェックで確認する。
活性化関数は「とりあえず ReLU」で止まらず、データ特性や勾配の挙動を観察しながら最適な関数にスイッチする姿勢が重要です。
次章では、誤差関数と誤差逆伝播法を深掘りし、ネットワークがどのように学習を進めるかを理解します。
誤差関数と誤差逆伝播法で学習メカニズムを深掘りする
ディープラーニングが高精度を実現できるのは、モデルの予測誤差を定量的に測る誤差(損失)関数と、その誤差を最小化する方向へ重みを更新する誤差逆伝播法(バックプロパゲーション)が密接に連携しているからです。
ここでは代表的な誤差関数を俯瞰し、逆伝播のアルゴリズムと学習を安定化するテクニックまでを体系的に解説します。
タスク別に最適な誤差関数を選ぶ
| タスク | 代表的な誤差関数 | 特徴 | 主な使用場面 |
|---|---|---|---|
| 回帰 | 平均二乗誤差(MSE) | 大きい誤差を二乗で強く罰する | 連続値予測(需要・価格) |
| 回帰 | 平均絶対誤差(MAE) | 外れ値にロバスト | メディアンが重要視される場合 |
| 二値分類 | バイナリ交差エントロピー | ロジスティック回帰と相性良好 | スパム判定・与信審査 |
| 多クラス分類 | カテゴリカル交差エントロピー | Softmax 出力と組み合わせ | 画像分類・感情分析 |
| 表現学習 | コントララスティブロス | 類似ペアを近づける | 顔認識・類似検索 |
| 表現学習 | トリプレットロス | アンカー+正例+負例を同時学習 | ファッション検索・認証 |
ポイント
- 交差エントロピーは「確率分布間のずれ」を測るため、出力が確率のときに最適です。
- MAE は外れ値の影響を抑えたいタスクで有効ですが、勾配が一定なので学習が遅くなることがあります。
誤差逆伝播法の流れを図解でイメージする
- フォワードパス
入力データが層を順番に通過し、予測値を計算します。 - 損失計算
予測値と正解ラベルを誤差関数に入力し、スカラー損失を求めます。 - バックワードパス
出力層から入力層へ連鎖律を用いて勾配を伝搬し、各層の重み勾配を計算します。 - パラメータ更新
勾配降下法系アルゴリズム(SGD、Adam など)で重みとバイアスを更新します。
この一連のプロセスを 1 イテレーション と呼び、すべての訓練データを 1 周すると 1 エポック が完了します。
勾配消失・勾配爆発への対策
| 課題 | 原因 | 代表的な対策 |
|---|---|---|
| 勾配消失 | シグモイドや tanh の飽和領域で微分値が極小 | ReLU 系活性化関数、残差接続、バッチ正規化 |
| 勾配爆発 | 重みが大きく更新され勾配が発散 | 勾配クリッピング、適切な初期化(He, Xavier) |
ヒント
- 残差接続(ResNet)の「スキップ接続」は、勾配の通り道を確保して消失を防ぎます。
- RNN 系では 勾配クリッピング が爆発抑制に必須です。
学習を加速・安定させるテクニック
- バッチ正規化
各バッチ内で出力を正規化し、内部共変量シフトを軽減します。収束が速く、初期学習率を高めに設定できます。 - ドロップアウト
訓練時にランダムでニューロンを無効化し、アンサンブル効果で過学習を抑制します。テスト時は全結合に戻します。 - ラーニングレートスケジューラ
学習率を段階的に減衰させるステップダウン法、精度が向上しなくなった時点で下げるReduceLROnPlateauなどが有効です。 - 早期終了
検証損失が一定エポック連続で悪化したら学習を停止し、最小値を記録したモデルを採用します。
コードを動かして理解を深める
# PyTorch で交差エントロピー + Adam を実装する例
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
for epoch in range(num_epochs):
for x, y in train_loader:
optimizer.zero_grad()
y_pred = model(x)
loss = criterion(y_pred, y)
loss.backward() # 誤差逆伝播
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=5.0) # 勾配爆発対策
optimizer.step()
このサンプルでは、損失計算 → backward() → 勾配クリッピング → step() という王道フローを確認できます。
実際に動かしてみると、学習率やバッチサイズを変えるだけで損失曲線が劇的に変わることを体感できます。
誤差関数と逆伝播の仕組みを理解すると、モデルが「なぜ学習できないのか」「どこがボトルネックになっているのか」を論理的に分析できるようになります。
次章では、モデル性能をさらに引き上げる正規化テクニックと最適化アルゴリズムを深堀りし、実務で即戦力となるチューニング術を解説します。
正規化テクニックと最適化アルゴリズムでモデル性能を最大化する

ディープラーニングはパラメータが膨大なため、過学習(オーバーフィッティング)と学習停滞が常につきまといます。
本章では ①モデルをシンプルに保つ“正規化” ②学習を速く安定させる“最適化” を体系化し、G検定の設問で「どの手法を選ぶべきか」を根拠を添えて答えられるレベルに引き上げます。
1. 正規化で汎化性能を高める
| 手法 | 目的 | 効果的なシーン | キーワードで覚えるポイント |
|---|---|---|---|
| L1正則化 | 不要重みをゼロ化 | 特徴量選択・モデル圧縮 | ラッソ回帰/スパース化 |
| L2正則化 | 大きな重みを抑制 | 連続値を扱う回帰全般 | リッジ回帰/Weight Decay |
| Elastic Net | L1+L2の折衷 | 高次元・相関高い特徴量 | ハイブリッド正則化 |
| ドロップアウト | ニューロンをランダム遮断 | CNN・MLP中間層 | 確率pで無効化/アンサンブル効果 |
| バッチ正規化 | 出力を標準化し内部共変量シフト軽減 | ほぼ全ネットワーク | 収束高速化/初期学習率↑ |
| レイヤー正規化 | シーケンス長の異なるRNN | 時系列・自然言語 | 特徴数で正規化 |
| 早期終了 | 検証損失悪化で学習打ち切り | 全タスク | patienceエポック/チェックポイント |
試験対策ヒント
- 「L1 と L2 の違い」を問われたら、L1=重みゼロ化 → 特徴選択、L2=重み縮小 → 安定学習をセットで答えます。
- バッチ正規化は「勾配が流れやすくなるため深層化が容易」という点に言及すると加点が望めます。
2. 最適化アルゴリズムで学習スピードを向上
2-1 基本系と改良系の立ち位置
- SGD(確率的勾配降下法)
- メモリ消費が小さく実装も簡単
- ノイズが大きく収束が遅い
- モメンタム/Nesterov
- “慣性”を付与し谷底を滑るように進む
- 振動を抑えながら学習率を保てる
- AdaGrad
- 過去勾配の二乗和でパラメータ別に学習率調整
- スパースデータに強いが後半に学習率が極小化
- RMSprop
- AdaGrad の減衰平均版で学習率枯渇を防止
- Adam
- モメンタム+RMSprop のハイブリッド
- ほとんどのタスクで“まず試す”定番
- AdamW
- Adam のWeight Decay誤用を修正し汎化性能を改善
- AdaBound/AMSBound
- Adam の初期高速+終盤SGD並み安定を両立
覚え方ワンフレーズ
- SGDは「シンプル・ノイズ大」、Adamは「自動調整で速い」、AdamWは「正則化が正しい」。
2-2 学習率スケジューリング
| スケジューラ | 特徴と利点 | 典型例 |
|---|---|---|
| ステップダウン | 指定エポックで段階的に減衰 | “10分の1”ルール |
| Cosine Annealing | コサイン曲線で徐減 | ResNet/Transformer |
| Warm Restarts | Annealing を周回させ局所解脱却 | SGDR |
| Cyclical LR | min↔max を往復し局所解脱却 | CLR |
学習初期は大きく、収束期に小さくするのが原則です。
G検定では「学習が停滞した際の改善策を選べ」という設問でスケジューラの知識を問われることがあります。
3. ハイパーパラメータ探索のベストプラクティス
- グリッドサーチ:モーラ的だが指数爆発
- ランダムサーチ:広範囲を低コストで探索、実務で◎
- ベイズ最適化:探索履歴を用いて次候補を推定、試験でのキーワード出題多数
ポイント
ノーフリーランチ定理を根拠に「万能アルゴリズムはない」ため、タスク特性に合わせて探索手法を切り替える必要があると説明できると高評価です。
4. 実務と試験に効くチューニング手順(5ステップ)
- シンプルなSGD+ReLUでベースラインを取り、訓練・検証損失の差をチェックします。
- 過学習が確認できたら L2正則化 → ドロップアウト を段階的に導入します。
- 収束が遅ければ Adam/AdamW+バッチ正規化 に切り替え、初期学習率を 3〜10 倍に設定します。
- 学習曲線が停滞したら Cosine Annealing または ReduceLROnPlateau を適用します。
- 検証損失が最小になった時点で 早期終了 を発動し、モデルを保存します。
この手順は試験のシナリオ問題で「最適な改善策を選べ」という設問にそのまま応用できます。
5. まとめ――“正則化”と“最適化”は車の両輪
- 正則化で“モデルを賢く絞る”
- 最適化で“学習を速く安定させる”
両者を組み合わせることで、精度向上と汎化性能、学習効率を同時に達成できます。
ディープラーニングは“巨大モノリス”に見えますが、実際には小さなレバー(ペナルティ係数・学習率)を調整することで性能が劇的に変わります。
G検定では「このレバーをどう動かすか」を論理的に説明できるかが合否の分水嶺です。
次章では、GPU・TPU など計算リソースの選定と高速化のコツを解説し、学習時間を短縮しながらコストを抑える実践知を紹介します。
GPU・TPUなど計算リソースの選定と高速化のコツ

ディープラーニングの学習時間と推論レイテンシは、ハードウェア選定と計算最適化によって大きく変わります。
ここでは最新の GPU/TPU 動向を踏まえつつ、プロジェクト規模別の推奨構成と学習を高速化するベストプラクティスを解説します。
1. 2025 年の主要ハードウェアカタログ
| 区分 | 製品例 | メモリ | 特徴 | 典型用途 |
|---|---|---|---|---|
| ノート向け GPU | RTX 5070 Mobile | 12 GB GDDR7 | 省電力・DLSS4 対応 | 学習プロトタイプ・小規模推論 |
| デスクトップ GPU | RTX 5090 | 32 GB GDDR7 | 1,999 USD・PCIe 5.0×16・4 NmFP16 180 TFLOPS | 中〜大規模モデル学習・生成 AI |
| データセンター GPU | H200 NVL | 188 GB HBM4 ×2 | NVLink4・FP8 8 PFLOPS | 数十億パラメータ LLM 訓練 |
| クラウド TPU | v5e | 16 GB HBM3/チップ | 1 チップ〜256 チップ PodInt8 100 POps/POD | RLHF・大規模推論クラスタ |
| クラウド TPU | v7 Ironwood | 32 GB HBM4/チップ | 2.5× v5e 性能・Vertex AI 統合 | 50B 以上の LLM 学習 |
選定の目安
- 〜100 M パラメータ:RTX 5070 Mobile でも十分
- 100 M〜5 B パラメータ:RTX 5090 単体またはマルチ GPU
- 5 B 以上:H200 NVL or TPU v5e/v7 Pod
2. ハードウェアを活かし切る高速化テクニック
| テクニック | 効果 | 適用ポイント |
|---|---|---|
| ミックスドプレシジョン(FP16/BF16) | メモリ半減・演算 2〜3 倍 | CNN・Transformer 共通。収束を確認しつつ実施 |
| Gradient Accumulation | 小 VRAM でも大バッチ実現 | RTX 5070 Mobile など VRAM 12 GB 以下環境 |
| データローディングの非同期化 | I/O ボトルネック解消 | num_workers を増やし CPU 側で前処理 |
| モデル並列・パイプライン並列 | LLM など巨大モデルを分割 | 深さ方向ならパイプライン、幅方向ならテンソル並列 |
| TPU Pod Mesh | All-reduce 帯域 50 TB/s 超 | Pod 化で 100 POps を一気に活用 |
3. クラウド vs オンプレのコスト比較(概算)
| シナリオ | 構成 | 学習 100 GPU 時間 | 参考コスト |
|---|---|---|---|
| オンプレ | RTX 5090 ×4 | 約 14 時間 | 電力+償却で 約 400 USD |
| クラウド GPU | H200 NVL ×2 | 約 4.5 時間 | 約 700 USD(オンデマンド) |
| クラウド TPU | v5e 32 チップ | 約 5 時間 | 約 550 USD(予約割引適用) |
オンプレは電力・冷却・運用工数を自己負担する点に注意が必要です。
短期集中で学習する場合はクラウドのスポット/予約インスタンスが総コストで優位になるケースが増えています。
4. 推論パイプラインの高速化
- 量子化 (8bit/4bit) でモデルサイズとレイテンシを圧縮
- TensorRT / XLA など専用コンパイラで演算グラフを最適化
- バッチ推論 + 非同期キュー でデバイス稼働率を向上
- キャッシュ埋め込み によるデータベース往復の削減
5. 実装チェックリスト
torch.cuda.amp.autocast()を有効化し OOM を確認torch.compile()でダイナミックシェイプを JIT 最適化- TPU 利用時は
pjrt://エンドポイントを指定 - 1 エポックごとに GPU/TPU メモリリークを確認 (
nvidia-smi,ctpu status)
6. まとめ
- ハード選定はパラメータ数と学習スケジュールで決める
- ミックスドプレシジョンとローディング最適化で RTX 5070 でも実用的な速度を確保できる
- クラウド GPU/TPU はスポット or 予約を活用し、実運用コストを最小化する
- 推論では量子化+専用コンパイラが即効性のある手段
次章では、2025 年新シラバスで指定されたキーワードをすべて網羅しつつ、ディープラーニング分野の学習ロードマップを提示し、合格ラインを越えるための最終チェックポイントを整理します。
2025年G検定新シラバス対応ディープラーニング学習ロードマップ

ディープラーニング分野は範囲が広く、何から手を付けるか迷いがちです。
本章では「限られた学習時間で合格点を確保する」ことをゴールに、5 週間×5 ステップの時系列ロードマップを提示します。
社会人学習者が平日1.5 h+週末4 hを確保できる前提で設計しているため、スケジュール調整も容易です。
| 週 | 目標 | 主要タスク | 推奨教材/ツール | 到達チェック |
|---|---|---|---|---|
| 1 | 基礎の全体像を掴む | - ニューラルネットワーク構造を図解- 活性化・誤差関数を一覧暗記 | - JDLA公式シラバス- 『深層学習教科書』序章〜第3章 | ✓ 用語カード50枚を即答 |
| 2 | 学習メカニズムを理解 | - 誤差逆伝播を手計算で追体験- 勾配消失/爆発を原因→対策で整理 | - YouTube講義 (逆伝播図解)- Colab: MLP実装 | ✓ 逆伝播の式変形を白紙で再現 |
| 3 | 性能向上テクニック習得 | - L1/L2・ドロップアウトをコード実装- Adam/Cosine LR を比較実験 | - PyTorch公式チュートリアル- TensorBoard で学習曲線可視化 | ✓ 損失曲線をスクショ+解説文作成 |
| 4 | 計算資源と高速化を体感 | - FP16訓練とGradient Accumulation- RTX or Colab TPU で速度差検証 | - Google Colab Pro (T4 or v3-8)- NVIDIA Nsight Systems | ✓ FP32→FP16で学習時間50%短縮 |
| 5 | 総仕上げと模試 | - 過去問160問を90分×2回- 弱点分野を暗記カードで反復 | - 公認テキスト2025年版- 市販模試アプリ | ✓ 2回目模試で正答率80%超 |
ロードマップを成功させる4つの鍵
- インプットとアウトプットを必ずセット
– 覚えた直後に「要点1分解説動画」をスマホで自撮りし、アウトプットすることで記憶が定着します。 - 学習曲線を可視化し、感覚ではなく数値で判断
– TensorBoard で損失と精度のグラフを見れば「どの設定が速く収束するか」が一目瞭然です。 - 週末は“実装+解説”のハイブリッド学習
– 例:土曜午前にCNNを実装→午後にコードを日本語コメントで丁寧に解説→日曜に模擬問題を解く。理解と記憶を往復させます。 - 直前3日間は新シラバス追加キーワードを重点確認
– 生成AI、TPU、FP8演算、RLHF などは時事性が高く差がつくポイントです。暗記カードと10問クイズで高速チェックします。
合格ラインを超えるための当日戦略
| 段階 | 時間 | 行動 | 目的 |
|---|---|---|---|
| 第1周 | 0–30 分 | 即答できる基礎問題を一気に回収 | 時間貯金を作る |
| 第2周 | 30–90 分 | シナリオ・計算問題を丁寧に処理 | 配点の高い中難度を死守 |
| 第3周 | 90–120 分 | マーク漏れ確認→見直し | ケアレスミスゼロ |
ワンポイント
試験システムはページ戻り可能ですが、ブラウザ更新でタイマーがリセット表示される事例が報告されています。本番前に必ず模試環境で操作感を確認しましょう。
受験後のキャリア展望
- E資格(エンジニア実装系)への挑戦
- Generative AI Testなど生成AI専門資格で差別化
- 社内DX推進チームでのリーダーシップ獲得
G検定合格はゴールではなくスタートです。本ロードマップを遂行し、合格後すぐ次のステップへ走り出せる準備を整えましょう。
学習者の皆さまがAI時代の波を乗りこなし、キャリアを加速させることを応援しています。
まとめと次の一歩を明確にする
ディープラーニング分野は、G検定の得点源であると同時に、今後の AI キャリアを切り開く核となる知識です。
本記事では、ニューラルネットワークの構造から活性化関数・誤差関数・正規化・最適化・計算リソース・学習ロードマップまで、2025 年版シラバスを完全にカバーしました。
最後に、合格後を見据えて行動指針を整理します。
合格後 30 日でやるべき3ステップ
- 公式コミュニティ CDLE に参加します
合格者限定 Slack で最新論文共有会や勉強会が定期開催されています。
知識アップデートと人脈形成を同時に進められます。 - ミニプロジェクトを企画・実装します
社内データや公開データセット(Kaggle 等)を用い、PyTorch で画像分類やテキスト要約を実装します。
ブログや Qiita にまとめるとポートフォリオとして評価されやすいです。 - 次の資格・研修に申し込みます
- E 資格:実装スキルを公式に証明
- Generative AI Test:生成 AI の最新動向をキャッチアップ
- MOOC(Coursera/edX):深層強化学習や MLOps を体系的に学習
長期的なキャリアパス例
| フェーズ | 目標 | 主な活動 | 目安期間 |
|---|---|---|---|
| 学習期 | G検定合格+実装演習 | ロードマップを完遂 | 3〜6 か月 |
| 実践期 | 社内 PoC の主担当 | 小規模モデルをプロダクション導入 | 6〜12 か月 |
| 拡張期 | 大規模案件の技術リード | E 資格・生成 AI 資格取得、LLM 活用 | 1〜2 年 |
| 発展期 | AI 戦略策定・事業化 | MLOps・ガバナンス導入、組織横断で推進 | 3 年〜 |
この記事を最大限活用するコツ
- ブックマークして「復習チェックリスト」として使います。
学習の進捗を見える化し、抜け漏れを防げます。 - セクションごとに “今日やること” を 1 行で書き出します。
抽象的な目標を具体的なタスクに落とし込み、行動を促進します。 - 仲間とシェアして議論します。
学習ロードマップを共有し、相互に質問し合うことで理解が深まります。
ディープラーニングは日進月歩で進化しますが、「基礎理論 × 実装経験 × 最新動向」をバランスよく学び続ければ、技術の波に乗り遅れることはありません。
G検定合格を起点に、AI を活用できるジェネラリストとして、そして将来的にはスペシャリストとして、さらなる高みを目指しましょう。
あなたの合格と成長を心から応援しています。
>今回紹介したG検定の学習内容以外を学びたい方は、こちらからご覧ください👇
